Loading blog...
Insurance Data Extraction: How AI Extracts ACORD Forms, Loss Runs, SOVs, and Claims Data at Scale

Vamshi Vadali
|
May 27, 2026
|
5 minutes read

“Insurance runs on documents. The question is whether your team is reading them or processing them.”
Insurance operations are built on documents. ACORD applications, loss runs, schedules of values, endorsements, claims forms, and certificates of insurance all contain operational data required for underwriting, claims adjudication, policy servicing, and compliance workflows.
Most insurers still process a large part of this information manually. According to a 2025 industry benchmark, 88% of auto insurers and 70% of home insurers report using or planning to use AI, yet only 7% have successfully scaled AI systems into production. The gap between pilot projects and full deployment is not a technology problem. It is a document problem.
Teams extract values from PDFs, emails, handwritten attachments, and broker submissions before entering them into AMS, PAS, or claims systems manually.
This slows underwriting cycles, increases operational overhead, and compounds entry errors across hundreds of weekly submissions. Insurance data extraction uses AI, OCR, NLP, and document intelligence to convert these unstructured documents into structured data that underwriting and claims systems can process automatically.
This guide covers how it works, where it fails at scale, and how to evaluate platforms for real commercial lines environments in 2026.
Key Takeaways
- Insurance data extraction goes beyond OCR. It includes document classification, entity recognition, multi-document reconciliation, and field-level validation.
- Commercial lines submissions fail when extraction systems process documents individually without reconciling data across linked files.
- ACORD forms, SOVs, loss runs, and endorsements each require different extraction logic.
- Multi-document reconciliation is the most critical and most commonly missing capability in insurance extraction platforms.
- Template-based systems break when brokers modify layouts or carriers use non-standard forms.
- Claims automation depends on accurate loss run extraction before adjudication workflows can run reliably.
What Is Insurance Data Extraction?
Insurance data extraction is the process of using AI, OCR, machine learning, and document intelligence to extract structured data from insurance documents such as ACORD forms, loss runs, SOVs, COIs, endorsements, and claims files before sending that data into AMS, PAS, or claims adjudication systems.
Standard OCR converts scanned text into machine-readable text. Insurance data extraction goes beyond this by identifying insurance-specific entities, classifying document types, reconciling information across multiple files, and validating extracted data before it reaches underwriting or claims workflows.
Our intelligent document processing overview explains how AI handles this document layer across complex, multi-file insurance packages.
Insurance documents are structurally difficult. They contain multi-page schedules, handwritten notes, coverage grids, broker-specific layouts, and non-standard carrier formats. This is why insurance workflows require more than a basic OCR engine.
What is the difference between insurance OCR and AI-powered insurance data extraction?
Insurance OCR converts document images into readable text. AI-powered insurance data extraction identifies insurance-specific fields, understands document context, classifies forms, and structures the extracted data for underwriting or claims workflows.
Example: An OCR engine may read the text from an ACORD 125 form, but an AI-powered extraction system identifies fields such as insured value, coverage limits, broker details, and effective dates before sending them into the PAS system.
Which insurance document types require IDP rather than standard OCR?
Documents such as loss runs, SOVs, endorsements, and commercial lines submissions require IDP because they contain variable layouts, multi-table structures, and handwritten information that standard OCR cannot process reliably.
Example: A handwritten loss run from a regional carrier may contain claim history spread across inconsistent table layouts. Standard OCR extracts raw text, while IDP systems classify claims, dates, reserve amounts, and settlement values into structured records.
“We have two people who do nothing but read incoming emails and route submissions to the right underwriter. They spend about 5 minutes per submission just figuring out what it is and who should handle it.” Underwriting Director, Mid-Sized Commercial Carrier
Source: V7 Labs, AI in Insurance Use Cases 2025
The biggest failure is not OCR accuracy. It is document isolation.
Most extraction systems work well on clean ACORD forms during demos. The problem begins with real commercial lines submissions containing multiple documents, carrier-specific formats, handwritten attachments, and complex schedules.
- Most systems process each document independently, even though underwriting decisions require data reconciliation across linked files.
An ACORD application, loss run, existing policy, SOV, endorsements, and broker cover note all need to be reconciled before the rating process begins. Without that, the underwriter still cross-checks everything manually. - Template-based systems fail when brokers modify layouts based on client requirements, when carriers use non-standard forms, when SOV tables span multiple pages, and when handwritten notes appear inside submissions.
- For teams processing 70 to 100 submissions weekly, this creates multiple additional working days spent on manual reconciliation. The extraction system removes keying but does not remove underwriting decision overhead.
📊 Insurance companies implementing AI underwriting systems have reduced processing times by up to 90%, from weeks to hours. Yet only 7% of insurers have successfully scaled AI systems into production, indicating the gap is in document handling, not AI capability.
Source: Appinventiv, AI in Insurance Underwriting 2026
What is multi-document chaining in insurance data extraction and why does it matter for underwriting?
Multi-document chaining links information across policy documents, loss runs, endorsements, and SOVs before underwriting decisions are made. Without reconciliation across documents, extracted data remains operationally incomplete.
Example: An underwriter reviewing a property submission needs to compare values from the SOV against historical claims in the loss run before approving coverage. Multi-document chaining connects these datasets automatically, removing the manual cross-referencing step.
Why does template-based insurance data extraction fail on commercial lines submissions?
Commercial lines submissions vary heavily across brokers and carriers. Template-based systems depend on fixed layouts, which break when document structures, coverage tables, or endorsement formats change.
Example: A broker may send a property SOV with merged cells and custom coverage columns. A template-based system fails to map values correctly, routing the submission for manual review and adding processing time that scales with submission volume.
Document AI that Eliminates Manual Processing and Compliance Gaps
How AI-Powered Insurance Data Extraction Works: From Document Intake to AMS or PAS Entry
Insurance extraction platforms follow a structured processing pipeline that converts raw insurance documents into validated data for underwriting, claims, and policy systems.
1. Document Ingestion and Classification
Documents enter the system through email, APIs, broker portals, or shared drives. The AI first classifies documents such as ACORD 25, ACORD 125, loss runs, endorsements, and SOVs.
Classification is one of the most critical stages because multi-document insurance packages often contain 8 to 15 separate files. If the system misclassifies an SOV as a generic attachment, it cannot be routed correctly into the underwriting workflow and the entire submission package requires manual triage.
2. OCR and Pre-Processing
The OCR layer converts scanned images into machine-readable text. Pre-processing improves image quality, removes noise, and detects tables.
This stage fails most often on handwritten loss runs where claims history is written manually, skewed scans where poor alignment distorts field detection, faxed claims documents with blurred text and inconsistent formatting, and low-resolution broker submissions where tables and handwritten fields cannot be detected reliably.
3. Field Extraction and Entity Recognition
The extraction engine identifies insurance-specific entities including policy numbers, insured names, effective dates, property values from SOVs, coverage limits, and claim reserves.
Our document data extraction capability handles entity-level identification across documents that contain multiple coverage tables and endorsement clauses in a single file.
This stage becomes difficult when coverage grids and endorsement language appear inside the same document as structured form fields.
4. HITL Validation and Confidence Scoring
Confidence scoring determines whether extracted fields can proceed automatically or require human review. Low-confidence fields are routed to human-in-the-loop validation workflows.
In insurance workflows, even small extraction errors can impact premium calculations, coverage validation, or claims settlement decisions.
HITL validation ensures that ambiguous values are reviewed before the data reaches underwriting or claims systems, improving accuracy without removing human oversight entirely.
5. Structured Output and AMS or PAS Integration
Validated data is pushed into AMS systems for policy and broker management, PAS platforms for policy servicing and billing, Guidewire for claims and underwriting operations, claims adjudication systems for settlement processing, and underwriting engines for risk assessment and premium calculation.
Our ERP and system integration layer connects structured extraction output directly into these platforms without manual reformatting. Structured integration removes manual re-entry and improves turnaround time across insurance workflows.
📋 If your underwriting team still manually keys SOV data before rating begins, or claims teams wait hours for loss run entry, the extraction layer is where operational delays are occurring.Book a demo to see how KlearStack handles underwriting and claims document workflows .
Insurance Document Types and What Each Requires from an Extraction System
Different insurance documents require different extraction capabilities. Systems that perform well on standard ACORD forms may fail on SOVs or handwritten loss runs.
| Document Type | Format | Key Fields Extracted | Extraction Complexity | What Breaks in Template Systems |
| ACORD 25 (COI) | Standard form | Coverage limits, dates | Moderate | Carrier-specific modifications |
| ACORD 125 | Commercial property | Risk details, insured data | Moderate | Additional broker attachments |
| ACORD 126 | General liability | Coverage data | Moderate | Custom schedules |
| Loss Runs | Structured and handwritten | Claims history | High | Handwritten layouts |
| SOV | Multi-table schedules | Property values | Very High | Merged cells, varying columns |
| Endorsements | Unstructured text | Coverage changes | High | Non-standard wording |
| Claims Forms | Mixed layouts | Claim details | High | Attachments and scanned images |
What makes Schedule of Values extraction more complex than standard ACORD extraction?
SOVs contain multi-table property schedules, custom columns, merged cells, and broker-specific layouts. Unlike standard ACORD forms, they rarely follow a consistent structure.
Each broker may organise the SOV differently, requiring the extraction system to identify and reconcile values regardless of column positioning or page breaks.
How does AI extract data from handwritten loss runs in non-standard carrier formats?
AI combines OCR, handwriting recognition, and contextual entity extraction to identify claim dates, reserve amounts, settlement values, and claim descriptions from handwritten carrier documents.
The system identifies what a field means based on its context within the document rather than its position on a fixed template.
📊 In a typical insurance company processing 10,000 claims monthly, AI-powered document processing reduces claims processing time from 48 hours to under 30 minutes per claim while achieving 99.9% accuracy through automated validation checks.
Source: FlowForma, Document Processing in Insurance 2025
Insurance Data Extraction Use Cases: Where Automation Delivers Measurable ROI
Insurance data extraction impacts multiple workflows across underwriting, claims processing, compliance, and policy servicing.
Automating document extraction reduces manual workload, improves turnaround time, and increases operational accuracy across insurance operations.
Claims Processing: Claims teams manually extract information from loss runs, claim forms, police reports, and supporting documents. AI extraction speeds up adjudication by converting these files into structured claim data while routing uncertain cases to HITL review.
The accounts payable automation principles that apply in financial workflows apply equally here: accuracy at the extraction stage determines reliability at every downstream stage.
Underwriting Support: Commercial underwriting depends on extracting data from ACORD applications, SOVs, endorsements, and prior policies. Automation reduces manual keying errors and improves quote turnaround before information reaches the rating engine.
Allianz UK’s AI tool saved approximately 135 working days of information gathering for underwriters in the first year of deployment.
COI Tracking and Validation: Real estate and contractor workflows often require validating hundreds of COIs during renewal cycles.
AI extraction automatically verifies coverage limits, effective dates, and named insured details across large document volumes without manual file-by-file review.
Policy Comparison: Insurance extraction systems compare expiring policies with proposed coverage structures to identify missing endorsements, exclusions, and policy changes before renewal or issuance.
This removes the manual side-by-side document review that slows down renewal cycles.
AMS and PAS Data Entry: Structured extraction pushes validated data directly into AMS and PAS platforms without manual re-entry, reducing operational overhead across high-volume workflows.
When extraction is automated correctly, underwriting and claims teams spend less time entering data and more time handling decisions and exceptions.
“Underwriters spend hours poring over boxes of submission documents to assess a new risk. Today, that process can be cut from hours to minutes with AI data extraction.” Ray Ash, Executive Vice President, Westfield Specialty
Source:Risk and Insurance, AI in Underwriting and Claims 2025
Document AI that Eliminates Manual Processing and Compliance Gaps
How AXA XL Automated Extraction Across 10,000 Site Survey Reports Annually
When document volume meets format variability in insurance, manual extraction does not scale. AXA XL provides a direct example of what happens when the extraction layer is automated at enterprise scale.
AXA XL enhanced property risk engineering capabilities by automating the process of data extraction from site survey reports. Before automation, the process of reading, extracting, and structuring data from risk engineering documents was handled manually across a team of underwriting operations staff.
Each report required extracting property characteristics, risk factors, and engineering assessment values before the data could inform underwriting decisions.
The AI system accelerates the analysis of more than 10,000 site survey reports annually. The extraction and structuring work that previously consumed significant underwriting operations capacity now runs automatically, routing structured risk data directly into underwriting workflows.
The result is not a faster version of the same manual process. It is a structurally different workflow where underwriters receive pre-extracted, structured data and focus their time on risk assessment and coverage decisions rather than document reading and field entry.
The document layer was the bottleneck. Fixing it removed the delay from every underwriting decision that depended on that data downstream.
(Source: CDP Center, Artificial Intelligence in Insurance: Trends and Case Studies 2025)
Your underwriting teams do not receive standardised submissions. Your claims files are not always digital. Your SOV layouts vary across brokers and carriers. KlearStack processes these documents without requiring template builds for every new format. Test extraction accuracy on your most complex insurance document types.
Step by Step Guide for Insurance Data Extraction with KlearStack
Here is the guide to process insurance policy documents with KlearStack to speed up the process and ensure accuracy.
Step 1: Register/login to the software
The first and foremost step is to register with the software. Once you have registered, you’ll receive login credentials. Use the credentials to log in with KlearStack and access its dashboard.
Step 2: View the dashboard

You can view and upload several document types in the dashboard, from invoices, insurance, receipts, and more. You can also create a customized document type based on your use cases. Navigate the insurance section in the dashboard and tap on it to upload the document.
Step 3: Add the Insurance policy document
Click on the “Add new” button at the top right corner to upload the document. KlearStack supports different document types, including PDF, Word, Excel, JPG, BMP, TIFF, PNG, scanned PDF, and ZIP.. You can upload the insurance document at your convenience.
Step 4: Select Type of Insurances & Number of Pages
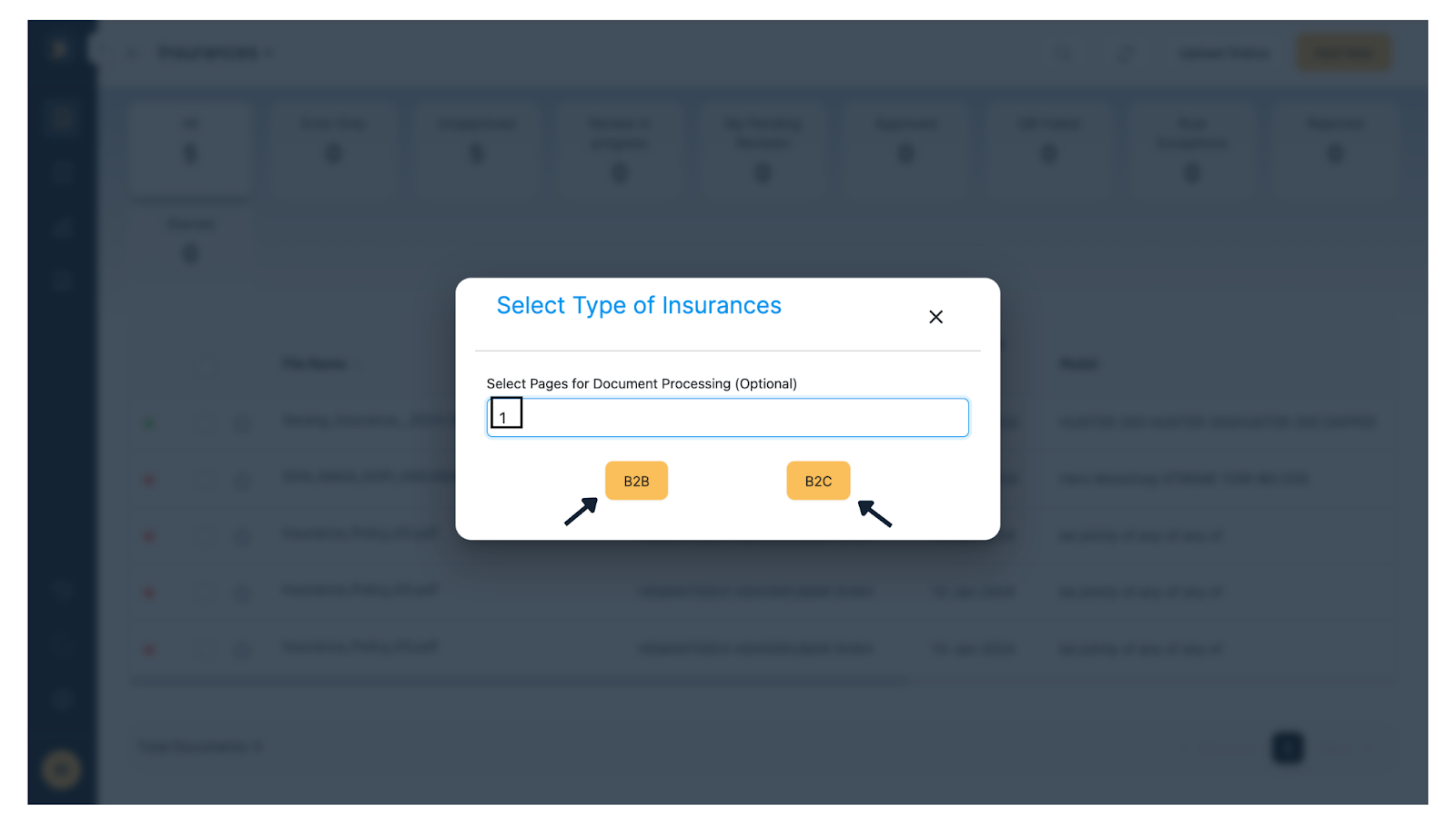
Select the type of Insurance whether it’s B2B or B2C. You also require to select the number of pages you want to process from uploaded documents. KlearStack can process multi page documents.
Step 5: View and verify the information
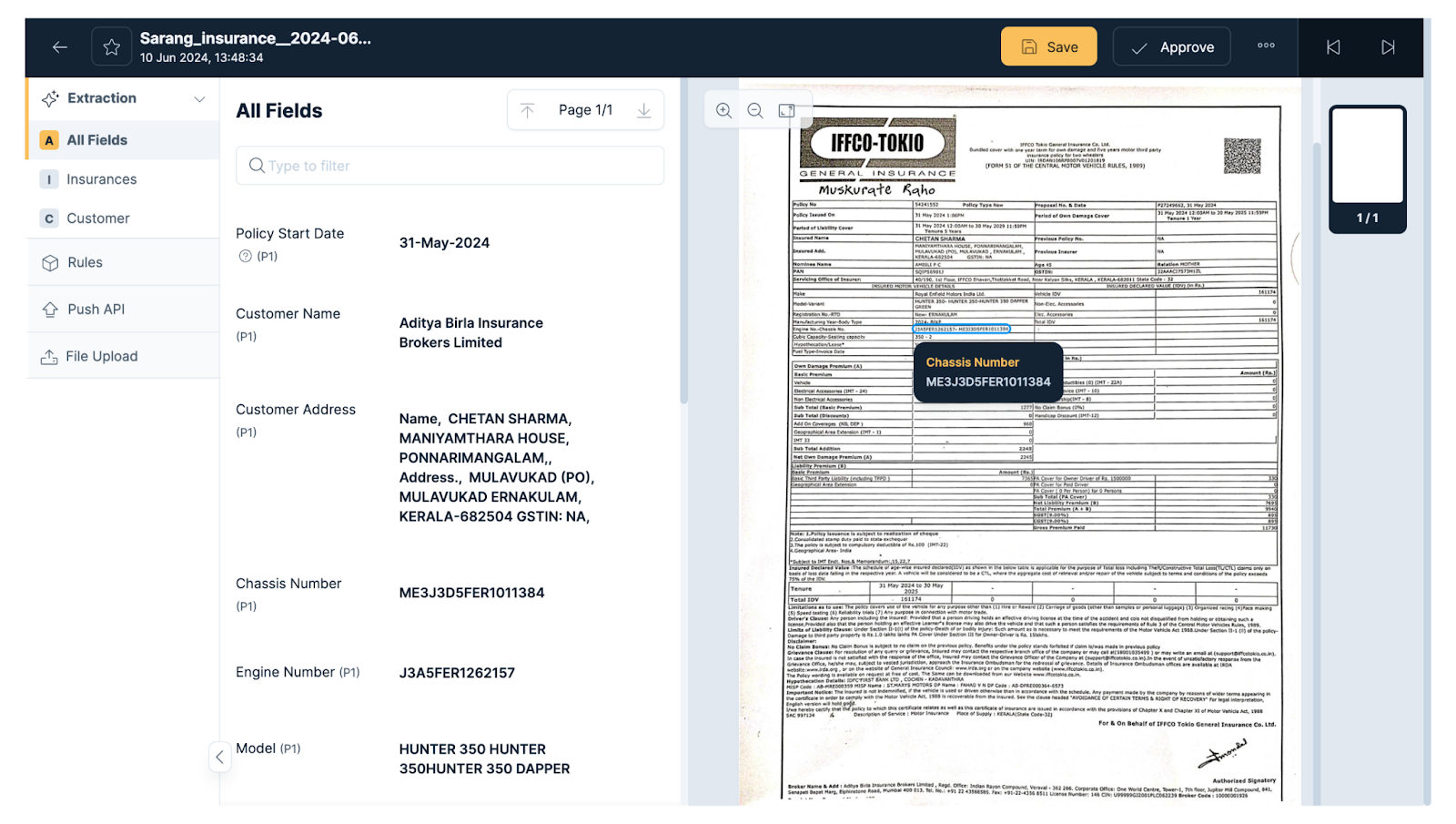
Once you upload the document successfully, the software extracts the information. View this information and verify its accuracy. If there is any misinformation, KlearStack enables you to correct it manually. Tap on the specific area to edit it.
Step 6: Manage the data in one place
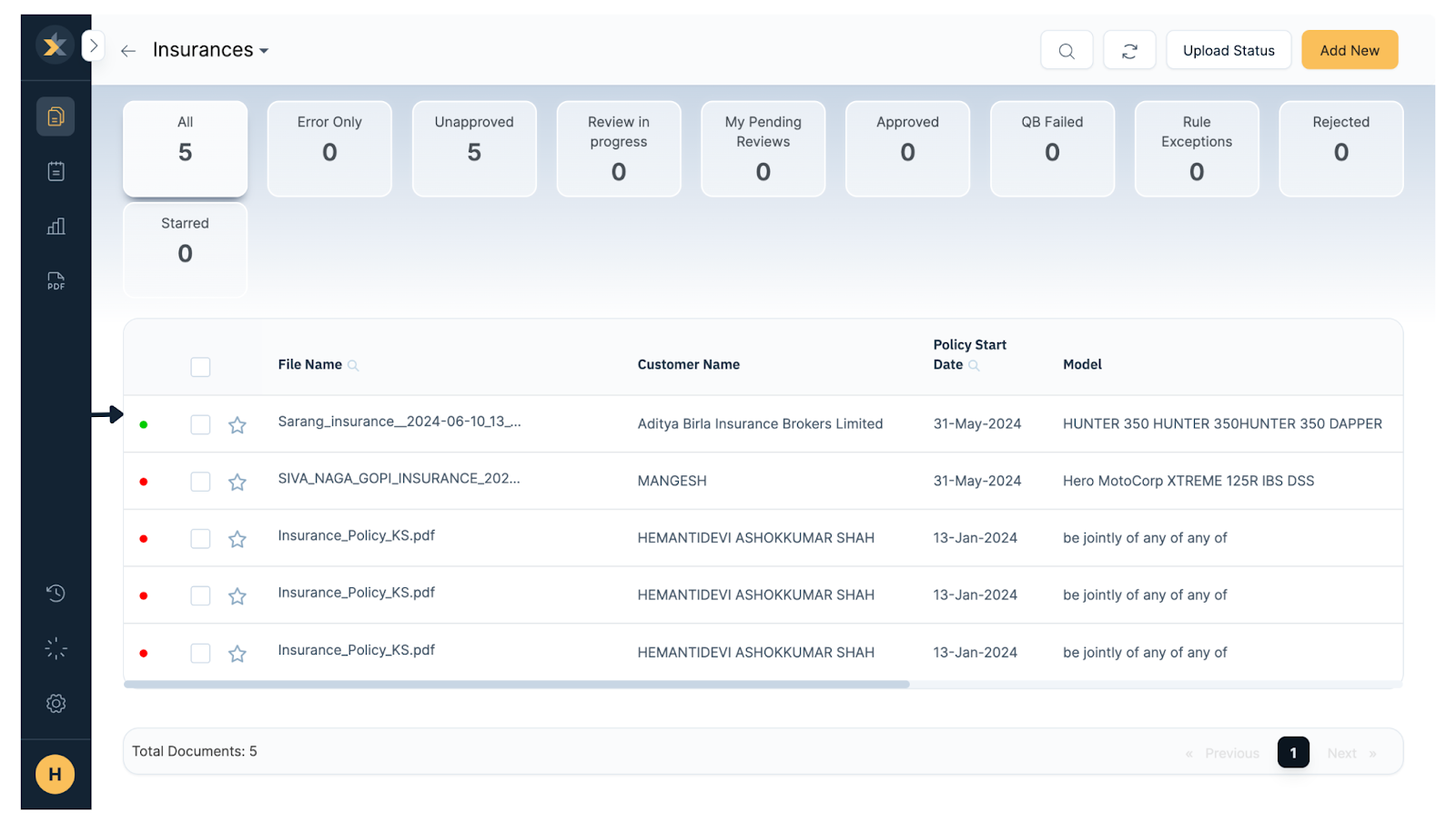
Through the KlearStack dashboard, you can manage all insurance policy documents in one place. You can see the document type, extracted information, and more to manage them efficiently.
Step 7: Use the Processed Data Conveniently
Now when the system has processed the data, you can access it and use it for different purposes. Klearstack also has the secure RESTful APIs, that enables you to integrate your existing system with Klearstack, automating the entire process.
Using RESTful APIs of Klearstack, you can upload documents for processing. KlearStack instantly processes those and pushes the extracted and audited results to your existing system using another API. There are also APIs with which clients can automate pushing the external data to KlearStack. KlearStack then uses this data for automated reconciliation against the data extracted from documents.
Key Benefits of Automated Insurance Data Extraction: What KlearStack Delivers Across Any Document Format
KlearStack is built for insurance workflows where document variability is operationally normal. It handles ACORD forms, handwritten loss runs, SOVs, endorsements, COIs, claims documents, and broker submission packages without requiring template configuration for each new format or carrier.
| Capability | What KlearStack Does | Underwriting and Claims Impact |
| Template-Free Extraction | AI models adapt to any carrier or broker format from the first document | New submission formats process without manual template setup |
| Pre-Trained Insurance Models | Domain-specific models for ACORD forms, loss runs, SOVs, and COIs | Insurance entities are identified accurately without generic document logic |
| Multi-Document Reconciliation | Links data across submissions, endorsements, SOVs, and loss runs before AMS entry | Underwriters receive reconciled data rather than individually extracted files |
| HITL Routing | Low-confidence fields route to human review before reaching underwriting systems | Extraction errors do not reach premium calculations or coverage decisions |
| AMS and PAS Integration | Direct connection to Guidewire, AMS360, PAS platforms, and ERP systems | No manual re-entry between extraction output and underwriting or claims systems |
| Compliance and Audit Trail | GDPR and DPDPA-compliant audit logs for every extraction and validation action | Every extracted field is traceable for regulatory and compliance review |
Your underwriting teams do not receive standardised submissions. Your claims files are not always digital.
KlearStack processes these documents without requiring template builds and pushes reconciled data directly into underwriting and claims systems before manual review begins.Your SOVs vary. Your loss runs are handwritten. Your broker submissions arrive in 12 different formats. KlearStack handles all of them without a single template build.
Conclusion
Insurance data extraction is no longer just an OCR problem. Modern underwriting and claims workflows depend on AI systems that can classify, reconcile, validate, and structure information across multiple insurance documents simultaneously.
The difference between a basic OCR tool and a true insurance extraction platform appears at scale. Commercial lines submissions, handwritten loss runs, multi-page SOVs, and endorsement-heavy policy packages require document intelligence that extends beyond simple text recognition.
FAQs
What is the difference between insurance OCR and AI-powered insurance data extraction?
Insurance OCR converts scanned text into machine-readable text. AI-powered extraction goes further by identifying insurance-specific fields, classifying document types, validating extracted information, and structuring data for underwriting or claims systems.
Which ACORD forms can be extracted automatically?
Most advanced systems extract data from ACORD 25, ACORD 125, ACORD 126, and ACORD 140. Accuracy depends on document quality, layout variation, and whether forms contain handwritten or broker-modified information.
How does multi-document reconciliation work in underwriting workflows?
It compares information across policies, endorsements, SOVs, and loss runs before data reaches underwriting systems. Without reconciliation, each document is extracted in isolation and the underwriter still performs the cross-referencing manually.
What accuracy benchmarks should insurers expect from extraction platforms?
Test on real production documents, especially handwritten loss runs and non-standard SOVs, not clean digital forms used during demos. Also evaluate how many documents still require manual review after extraction.
Vamshi Vadali
Vadali Vamshi is a technology writer specializing in AI-powered document processing, intelligent automation, and OCR solutions. He helps businesses simplify complex document workflows through clear, insightful, and actionable content. Passionate about emerging trends in Document AI, Vadali writes extensively on how intelligent document processing accelerates efficiency and compliance across industries.