Loading blog...
How to extract data from a Purchase Order?

Vamshi Vadali
|
April 17, 2025
|
5 minutes read

Purchase Order (PO) is a legal contract/agreement of a transaction between a buyer and a seller. If any errors occur while capturing data from this document, it can have a significant impact on the business.
With various departments submitting their purchase requirements, accounts payable teams often have to handle a huge number of POs. Processing all these documents accurately is nearly impossible when done manually.
However, automated tools for PO data extraction make accurate processing achievable. These tools can handle a vast number of documents simultaneously, reducing errors by 90%.
They also increase processing speed by a factor of five by minimizing manual data entry by 80%. Increased efficiency leads to better productivity overall, which results in revenue growth.
In this blog, we will learn more about the concept of PO data extraction, its benefits, and how it can be effectively implemented using KlearStack.
What is Purchase Order Data Extraction?

Purchase order data extraction is transferring information from documents into the system, connecting further processing. This task can be done manually or automatically through automated software and tools available for this process.
Data extraction process through automated tools is necessary for documents like purchase orders. There is a high level of accuracy required in capturing this data which can be achieved through automated tools.
Manual PO Data Extraction vs Automated PO Data Extraction

Manual data extraction
Manual PO data extraction is the process of entering the information in the system from the documents manually. This involves checking each field and entering the corresponding information into whichever system the organization is using for further processing.
Automated data extraction
Automated PO data extraction relies on Intelligent document processing (IDP) to process purchase orders. Using Artificial Intelligence (AI) and Machine Learning (ML), these tools convert data into digital formats for easier processing.
By accurately extracting data from documents, they minimise errors and decrease the need for manual tasks. This results in the better adoption of Enterprise Automation, which leads to faster and more efficient operations.
How does Purchase Order data extraction software or tools work?
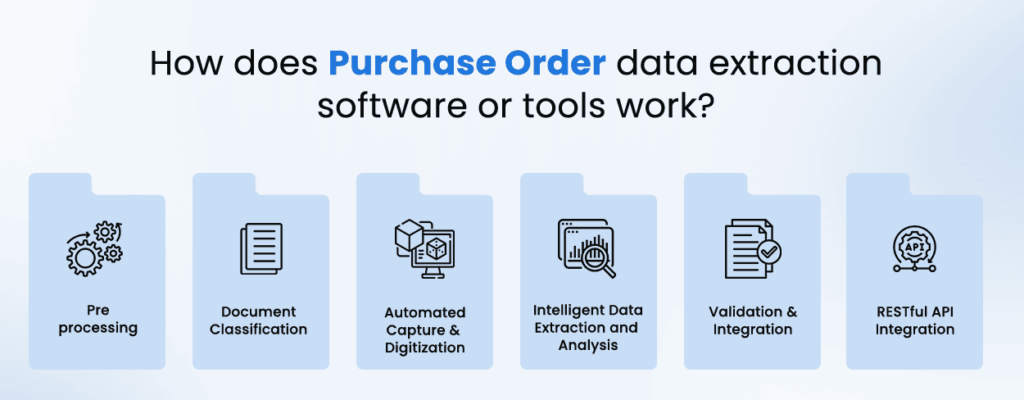
The Purchase Order data extraction tools make use of advanced technologies available, such as Artificial Intelligence (AI) and Machine Learning (ML). Additionally, Optical Character Recognition (OCR) is used which ensures better results in data capture.
KlearStack stands out as a comprehensive solution for the data extraction process from various documents, including important ones like purchase orders. It accurately collects and enters all the sensitive information with high precision.
Here is the process to understand how data extraction is done with KlearStack:
Pre-processing
Pre-processing gets a scanned or photographed PO image ready for further analysis. This step involves reducing noise, enhancing the image, and aligning it for clarity and uniformity. These improvements ensure accurate character recognition and data extraction in subsequent stages.
Document Classification
Document classification is a process where the categorization of documents is done. It involves identifying the document type such as receipts, invoices, and purchase orders, etc., and putting them in the correct category.
Machine learning algorithms are often employed to recognize patterns and features unique to each document type. Proper classification ensures the correct extraction rules and templates are applied for accurate data processing.
Automated Capture & Digitization
Automated capture and digitization is a step where a physical purchase order gets converted into a digital format using OCR technology. This process scans the document to create a machine-readable text version, which can then be stored and managed electronically.
The digitized data serves as the foundation for further processing and analysis.
Intelligent Data Extraction and Analysis
Intelligent data extraction and analysis involve identifying and extracting key details from digitized purchase orders, such as dates, amounts, shipping information, and delivery terms.
Advanced algorithms and machine learning techniques ensure accurate identification and interpretation of these fields. The extracted data is then analyzed to verify its completeness and accuracy.
Validation & Integration
Validation and integration ensure the extracted data is accurate and ready for use in other systems. In this process extracted data is verified against existing databases, to identify errors and ensure that the data meets predefined business rules.
After validation, this data is integrated into enterprise resource planning (ERP) systems, accounting software, or other platforms that the organization might be using.
RESTful API Integration
RESTful API (Application Programming Interface) integration allows the purchase order OCR system to communicate and exchange data with other software applications online.
By providing a standardized connection method, APIs enable smooth integration of OCR functions into existing workflows.
Due to this automation, data is transferred automatically. This minimizes manual efforts and increases overall efficiency.
Benefits of using Automated Data Extraction From Purchase Orders
Purchase Orders have legal implications – hence, any errors in their processing result in serious consequences for businesses. Therefore, finding a reliable method to prevent these issues becomes a necissity, and that’s where purchase order automation comes handy.
The advanced technologies used in these tools manage the entire process very well. AI, ML, and OCR help in automating this process with minimal human intervention.
Automated data extraction benefits organizations in the following ways:
- Improved Accuracy and Compliance
Automated systems reduce the risk of errors in PO processing, ensuring that all details such as item quantities, prices, and delivery dates are accurately captured. This precision helps maintain compliance with contractual obligations and regulatory requirements, reducing the likelihood of disputes and financial penalties.
- Cost Reduction
By minimizing manual data entry and associated labor costs, automated PO processing leads to significant cost savings. Additionally, the reduction in errors and the ability to process POs more quickly help avoid costly delays and corrections.
- Enhanced Supplier Relationships
Accurate and timely processing of POs fosters better relationships with suppliers. Automated systems can quickly generate and send POs, ensuring that suppliers receive clear and accurate orders, which can lead to more reliable and efficient supply chains.
- Scalability
As businesses grow and the volume of POs increases, automated systems can easily scale to handle the additional workload. This scalability ensures that the PO processing remains efficient and effective, regardless of the number of orders being managed.
Step-by-Step Guide to Extract Data from Purchase Orders Using KlearStack
Features of KlearStack’s PO OCR

1. Template-less Solution
Invoice OCR by KlearStack has a template-less solution, which means that it can extract data from any new PO layout accurately. Model retraining is not required every time. It can handle varied types of designs and adjust to new layouts as required. This saves time and resources.
2. Multi-lingual Support
KlearStack provides support for 50 languages for PO data extraction. Languages supported include English, Hindi, Marathi, French, German, Chinese, Japanese, and more. When businesses have operations with overseas suppliers, this feature becomes of great importance. Multi-lingual support ensures that language barriers do not hamper efficient PO processing.
3. Bulk Purchase Order Processing
With this feature of KlearStack’s PO OCR, multiple POs can be processed at once.
This increases the speed of the overall process and a large number of POs can be processed in one go with better efficiency and in less time.
4. Line-item Data Extraction
This ensures all the vitall line items are extracted correctly from the POs. These items include product descriptions, quantities, unit prices, total amounts, etc. This accurate data extraction is crucial for financial analysis and inventory management. It is also important to ensure that the items on the PO match the invoiced items and received goods.
5. Multi-page Data Extraction
KlearStack’s PO OCR offers support for multi-page data extraction. This ensures data is extracted with precision across all pages. This feature is specifically essential for large POs or those with extensive itemized lists, ensuring that no critical information is overlooked.
6. Self-Learning Algorithm
KlearStack has a continuously learning AI and it keeps improving its accuracy over time. As it processes more POs, it becomes better at identifying and extracting relevant data points. This feature eliminates the need for constant manual intervention.
7. Seamless Integration
KlearStack’s Invoice OCR can be easily integrated with your existing ERP and accounting systems. Because of this integration, extracted and validated invoice data directly gets transferred into financial management systems. This cuts down on the need for manual data entry. This boosts the overall productivity and efficiency of the processes.
8. Document Classification
In document classification, it becomes possible to categorize the document based on its content. KlearStack’s PO OCR is trained to identify the documents as purchase orders, invoices, receipts, or other relevant categories. This helps in better organization of documents and streamlines the process for all the relevant departments.
9. Automated Document splitting
Because of this feature provided by KlearStack, it becomes possible to separate a PO from other documents that may be attached to it such as an invoice or receipt. When it is essential to analyze the data from each page, this feature proves to be a boon.
10. Rich Document Audit Engine
Audit Engine provides you with an option to set rules for auditing or checking the extracted data against it. If the data meets the rules or conditions that are set it is processed further, if it does not meet then that particular case is flagged for review.
11. Rules-based workflows
Rules-based workflows are a systematic way to route a particular bunch of data or documents to the appropriate team or member. Here you can set up criteria based on different specifics, such as the total amount, the name of the supplier, or any other relevant condition.
Based on these criteria your documents will be automatically processed without the need for human intervention.
Why Should You Choose KlearStack?
KlearStack is a one-stop solution for your PO data extraction requirements. It extracts the data with precision and categorizes it properly for further processing. You can upload POs in any format, semi-structured or unstructured, and KlearStack will process them with significant accuracy.
It supports over 50 languages and expertly trained models extract data seamlessly.
Curious about how KlearStack achieves this? We invite you to test our system in a Free Demo with any PO format, structured or unstructured.
Experience KlearStack’s exceptional data extraction capabilities.
Yes, we’re ready to undertake this blind test.
Frequently Asked Questions (FAQs)
1. Can automated purchase order extraction extract data from a PDF?
Yes, automated PO data extraction systems, like those provided by KlearStack, can extract data from a PDF and other formats such as Word, Excel, JPG, BMP, TIFF, PNG, and ZIP.
2. What are the benefits of using automated data extraction software for extracting data from purchase orders?
There are many benefits of using automated software, but 3 prominent of those are time-saving, and a much lesser rate of errors. and cost reduction. These lead to better efficiency and growth in revenue for the company.
3. Does automated PO data extraction support multiple languages?
Yes, many automated PO data extraction tools support multiple languages. For example, KlearStack supports over 50 languages, making it suitable for businesses operating in diverse regions or dealing with international suppliers.
Vamshi Vadali
Vadali Vamshi is a technology writer specializing in AI-powered document processing, intelligent automation, and OCR solutions. He helps businesses simplify complex document workflows through clear, insightful, and actionable content. Passionate about emerging trends in Document AI, Vadali writes extensively on how intelligent document processing accelerates efficiency and compliance across industries.