Loading blog...
What is Data Extraction? Complete Guide + Tools & Examples 2025

Vamshi Vadali
|
July 21, 2026
|
5 minutes read

Data extraction means gathering data from various sources and moving it to a centralized location for analysis and storage. According to Gartner, organizations lose approximately $15 million annually due to poor data management. Companies today face a critical challenge — efficiently extracting and using this vast amount of information for insightful business decisions.
- Are you struggling to consolidate scattered data from multiple platforms?
- Do you frequently encounter data quality issues?
- Is the manual handling of large datasets affecting your productivity?
The extraction of data is crucial for transforming raw data into actionable insights, ensuring informed decisions, accurate analytics, and enhanced operational performance.
What is Data Extraction?

Data extraction is the process of systematically gathering specific, relevant data from various sources and moving it to a single, centralized location for storage, processing, and analysis. It is the crucial first step in data integration, ETL processes, and business intelligence workflows that transforms scattered information into usable formats.
The process involves collecting data from diverse sources including databases, websites, files, APIs, and applications. This data can be structured like spreadsheets and databases, unstructured like documents and emails, or semi-structured like JSON and XML files. The extracted information is then prepared for transformation and analysis.

Data extraction serves multiple business purposes beyond simple data collection. It enables organizations to consolidate information scattered across different systems, departments, and platforms. This consolidation creates comprehensive datasets that provide complete views of business operations, customer behavior, and market trends.
Modern data extraction processes often involve sophisticated techniques to handle various data formats and sources. The extracted data maintains its integrity while being prepared for subsequent transformation and loading phases that make it suitable for analysis and decision-making purposes.ons.
Key Aspects of Data Extraction
Understanding the fundamental components of data extraction helps organizations implement effective data management strategies that align with their specific requirements and objectives.
Data Sources: Data can be extracted from numerous sources, including databases, spreadsheets, cloud platforms, APIs, websites, log files, and text documents. Each source type requires specific extraction approaches based on its structure, access protocols, and data format.
Common Source Categories:
- Databases including SQL, NoSQL, and cloud-based systems containing structured business information
- Spreadsheets and flat files with organized data in rows and columns
- Web pages and APIs providing dynamic information through structured interfaces
- Log files and text documents containing unstructured or semi-structured information
- SaaS platforms like CRM and ERP systems with business-specific data
Data Types: Organizations extract three primary data types, each requiring different handling approaches and techniques for optimal results.
Structured Data: Information organized in fixed fields with consistent formats like database tables and CSV files. This data is easily queryable and integrates smoothly with analytical tools and reporting systems.
Unstructured Data: Information without predefined organization including emails, documents, images, and social media content. This data requires specialized processing techniques to extract meaningful insights and convert into usable formats.
Semi-Structured Data: Information with some organizational elements but lacking rigid structure like JSON files, XML documents, and web page content. This data requires parsing and schema detection for effective extraction and processing.
Purpose and Goals: Data extraction serves specific organizational objectives that drive business value and operational improvements.
Primary Objectives:
- Consolidating scattered information into centralized repositories for comprehensive analysis
- Preparing raw data for transformation and cleaning processes that ensure quality and consistency
- Enabling integration between disparate systems and platforms for unified data access
- Supporting real-time decision-making through timely data availability and accessibility
- Creating foundations for business intelligence and analytics initiatives
Role in ETL/ELT Processes: Data extraction forms the foundation of both ETL and ELT workflows, determining the success of downstream processing and analysis activities.
ETL Integration: Extract, Transform, Load processes begin with data extraction that gathers information from source systems. The extracted data then undergoes transformation for cleaning and formatting before loading into target destinations like data warehouses.
ELT Integration: Extract, Load, Transform processes also start with data extraction but load raw data directly into target systems before transformation. This approach leverages the processing power of modern cloud platforms for data transformation activities.
Document AI that Eliminates Manual Processing and Compliance Gaps
Why is Data Extraction Important?
Data extraction drives organizational success by enabling comprehensive data utilization, informed decision-making, and operational efficiency improvements across all business functions.
Unifying Data Sources: Organizations typically store data across multiple systems, platforms, and departments. Data extraction consolidates scattered information into single locations where it can be analyzed comprehensively and used effectively for strategic initiatives.
Consolidation Benefits:
- Eliminates data silos that prevent comprehensive analysis and insights
- Creates unified datasets that provide complete business operation views
- Enables cross-functional collaboration through shared data repositories
- Reduces redundancy and inconsistencies across different systems
- Improves data governance and management through centralized control
Enabling Analysis and Business Intelligence: Raw data stored in various formats and locations provides limited value until extracted and prepared for analysis. Using AI for Document extraction makes information accessible to business intelligence tools and analytical processes that generate actionable insights.
Analysis Capabilities:
- Powers reporting dashboards with current and historical data from multiple sources
- Enables predictive analytics through consolidated datasets that reveal patterns and trends
- Supports decision-making with comprehensive information that spans entire organizations
- Facilitates compliance reporting through complete audit trails and data lineage
- Improves customer understanding through integrated data from all touchpoints
Improving Efficiency and Automation: Manual data collection and processing consume significant resources while introducing errors and delays. Automated data extraction processes reduce manual effort while improving accuracy and consistency across data workflows.
Efficiency Gains:
- Reduces manual data entry and collection time by automating repetitive tasks
- Minimizes human errors through consistent automated processes
- Accelerates data availability for time-sensitive business decisions
- Scales data processing capabilities without proportional resource increases
- Frees staff to focus on analysis and strategic activities rather than data collection
Supporting Decision-Making:
Timely access to accurate, comprehensive data enables organizations to make informed decisions based on complete information rather than partial or outdated datasets.
Decision Support:
- Provides real-time visibility into business operations and performance metrics
- Enables data-driven strategies based on comprehensive information analysis
- Supports competitive advantage through faster access to market and customer insights
- Improves risk management through complete data visibility and analysis
- Enhances operational planning through historical data and trend analysis
Types of Data Extraction
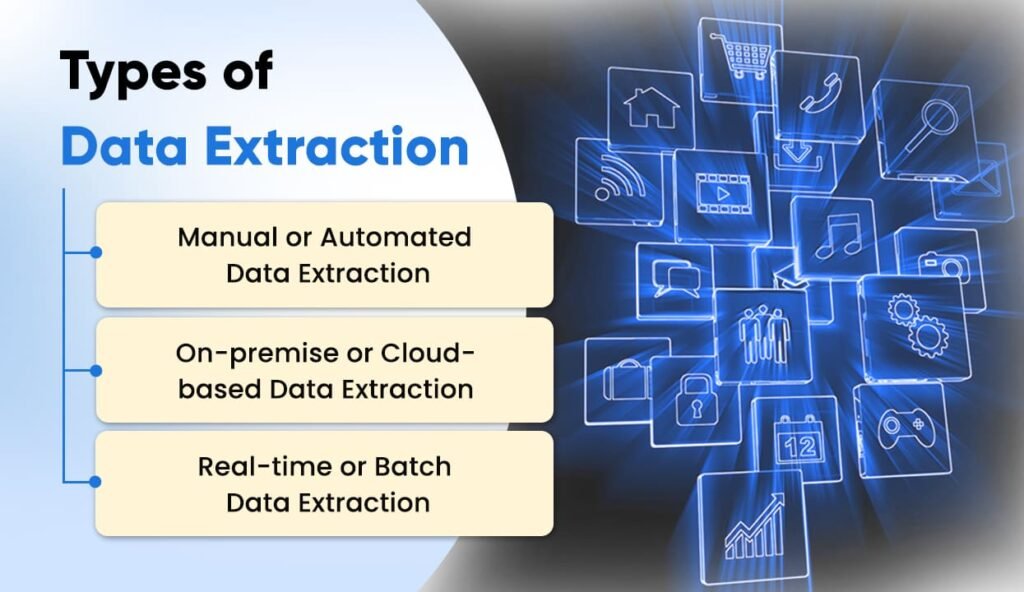
Data extraction methods can be categorized into three primary types:
Full Extraction
This method involves retrieving all data available from the source. Ideal for initial data migrations, it ensures completeness and accuracy but can be resource-intensive.
Incremental Extraction
Incremental extraction captures only data changes since the last extraction. This approach reduces system load and is ideal for regularly updated datasets.
Web Scraping
Web scraping automates the extraction of data from websites. It’s essential for gathering data not directly accessible via traditional APIs or databases.
Overview of Popular Data Extraction Tools
Popular data extraction tools offer efficient ways to gather and change unstructured data. They change it into structured formats for analysis.
KlearStack
KlearStack allows users to extract information from unstructured and semi-structured documents with ease and high precision. What makes it unique is its template-less feature.
Document AI that Eliminates Manual Processing and Compliance Gaps
Why Should You Choose KlearStack?
KlearStack provides advanced data extraction capabilities specifically designed for document processing and unstructured data handling with superior accuracy and efficiency.

Template-Free Document Processing KlearStack’s AI-powered technology processes any document format without requiring pre-configured templates. The system adapts automatically to different layouts, structures, and content types commonly found in business documents.
Advanced Processing Capabilities:
- Intelligent document classification identifying document types automatically without manual configuration
- Dynamic layout recognition adapting to varying document structures and formats
- Multi-language support processing documents in multiple languages with consistent accuracy
- Complex document handling including multi-page documents with mixed content types
- Line-item extraction capturing detailed information from tables and structured data sections
Superior Accuracy and Self-Learning Advanced machine learning algorithms continuously improve extraction accuracy while reducing manual intervention and error rates.
KlearStack offers secure, compliant document handling to meet diverse business requirements. Ready to enhance your data extraction capabilities? Book a free demo today.
Import.io
Simplifies web data extraction, turning unstructured data into structured formats.
Octoparse
Provides a user-friendly interface for scraping dynamic websites efficiently.
Parsehub
Specializes in extracting data from JavaScript and AJAX pages, integrating it into various applications.
OutWitHub
Offers sophisticated scraping functions with an intuitive interface.
Web Scraper

Automates data collection processes and saves data in multiple formats like CSV, JSON, etc.
Mailparser
Extracts data from emails and files, automatically importing it into Google Sheets for easy access and analysis.
Data Extraction and the ETL Process
Data extraction serves as the first step in the Extract, Transform, Load (ETL) process:
- Extraction: Data is collected from various sources.
- Transformation: Data is cleaned and formatted for usability.
- Loading: Prepared data is moved to a storage destination, typically a data warehouse.
A clear understanding of ETL helps organizations effectively leverage their data assets.
Data Extraction Techniques
Data extraction involves getting data from various sources. Several techniques can be used. The choice depends on the type of the data and the source.
Here are the main techniques for data extraction:
Association: This technique finds and pulls out data. It does this based on the relationships and patterns between items in a dataset. It uses parameters like “support” and “confidence” to find patterns that help in extraction.
Classification: It is a widely used method. Data is put into predefined classes or labels using predictive algorithms. Models are then trained for classification-based extraction.
Clustering: This unsupervised learning technique groups similar data points into clusters. It does this based on their characteristics. It is often used as a step before other data extraction algorithms.
Regression: Regression models relationships. It does this between independent variables and a dependent variable in a dataset.
Use Cases of Data Extraction in Various Industries
Alpine Industries, a leading manufacturer, faced a task, where they extract data from PDF documents daily. The in-house team of the company was responsible for processing these documents manually into their ERP (Enterprise Resource Planning) system.
The task was time consuming and impacting employees productivity. To overcome this challenge, Alpine Industries introduced a comprehensive data management platform to streamline the entire data process.
Similar like Alpine, there are multiple other sectors that have simplified their data extraction processes through automation:
Retail: Retailers can extract pricing data from competitors’ websites. This data allows for strategic price adjustments. These adjustments improve competitiveness and profitability.
Healthcare: Gathering patient feedback from online sources improves care. It helps by finding areas to improve.
Finance: Collecting market data helps make better investment decisions. It also aids in portfolio optimization for banks.
E-commerce: Analyzing customer behavior guides product offerings and marketing strategies, driving sales.

Challenges and Considerations in Data Extraction
Extracting data is a neccessity. But, despite advancements, many issues make it hard for businesses:
1. Data Diversity
Managing various data formats and structures poses a tiringchallenge in data extraction. Sources may use different formats. For example, CSV, JSON, and XML. They may also use different structures. For example, relational databases and NoSQL databases.
This requires good extraction processes to handle the diversity well.
2. Quality Assurance
Ensuring data accuracy, completeness, and consistency is crucial for reliable analysis and decision-making. But, getting data from many sources raises the risk of errors. For example, data can be missing or wrong. We must implement quality assurance measures.
They will validate and clean extracted data to keep it reliable.
3. Scalability
Efficiently handling large data volumes is useful. Data volumes continue to increase with evolution of tech.. These tasks need scalable infrastructure and optimized processes. This is to prevent bottlenecks and ensure timely data delivery. They involve extracting, processing, and managing massive datasets.
4. Security and Compliances
Following data standards is another neccessity. This includes regulations for data extraction. These requirements, like GDPR, HIPAA, and PCI DSS, have strict rules. They cover handling sensitive data. Protecting sensitive information during data extraction is important. It prevents unauthorized access, data breaches, and privacy violations.
This helps in reducing legal and reputational risks from non-compliance. Implementing strong security should include encryption, access controls, and secure protocols.
5. Legacy System Integration
It’s hard to combine old and new tech in data extraction. Legacy systems may use old or proprietary formats and interfaces. This makes integrating them with modern extraction tools and platforms hard and slow. Overcoming compatibility issues is very important.
You must ensure smooth integration to extract data from legacy systems well.
6. Budget Constraints
Businesses must balance costs with the need for effective extraction. Buying strong extraction tools, infrastructure, and security can cost a lot. This is especially true for small and medium-sized enterprises with limited budgets. Finding affordable solutions ensures profit.
They must meet data extraction needs without sacrificing quality and security.
Conclusion
Data extraction techniques retrieve and combine information from many sources. This enables analysis, manipulation, and storage for many purposes. It is broadly divided into automated and manual extraction methods. It uses tools like SQL for relational databases.
It is the first step in the ETL process. Data extraction makes data handling efficient. This ensures accurate and timely insights for informed decisions.
Key takeaways include:
- Significant improvement in data quality.
- Enhanced strategic decision-making capabilities.
- Cost-effective and efficient analytics.
As discussed earlier, there are many extraction techniques. You can take your pick based on your specific set of requirements.
Using effective data extraction methods can lead to substantial operational and financial benefits.
Vamshi Vadali
Vadali Vamshi is a technology writer specializing in AI-powered document processing, intelligent automation, and OCR solutions. He helps businesses simplify complex document workflows through clear, insightful, and actionable content. Passionate about emerging trends in Document AI, Vadali writes extensively on how intelligent document processing accelerates efficiency and compliance across industries.