

Zonal OCR, also known as Template OCR, is a specialized Optical Character Recognition technique that targets specific “zones” within a document for data extraction.
By focusing on predefined areas, Zonal OCR captures structured information from scanned documents with greater accuracy compared to traditional OCR methods that process entire documents indiscriminately.
Applying Zonal OCR during data capture can greatly expand accuracy and speed in processing (According to Accusoft’s Blog post [1]).
Additionally, automating data extraction tasks with Zonal OCR not only saves time but also prevents data entry errors (According to the report published by Upland Software [2]).
But you must have thought of the following questions:
- Have you faced repeated errors while manually processing forms?
- Are fixed-layout documents still processed manually at your business?
- Do your teams spend excessive hours extracting structured data from documents?
Manual data entry and traditional OCR methods often lead to inefficiencies and errors. Zonal OCR addresses these issues by extracting precise information from predefined zones within documents, making data more reliable and accessible for immediate business use.
Key Takeaways
- Zonal OCR extracts structured data from predefined document zones.
- Improves accuracy significantly compared to traditional OCR.
- Ideal for structured documents like invoices, IDs, and purchase orders.
- Not suitable for documents with varying layouts.
- KlearStack offers advanced Zonal OCR with AI capabilities for complex data extraction.
What Exactly is Zonal OCR?
Zonal OCR is a type of Optical Character Recognition technology. It reads and extracts text from designated regions or “zones” in scanned documents. Businesses define these zones based on their data extraction needs.
Unlike traditional OCR, Zonal OCR converts scanned document data into structured formats like JSON or XML. This structured output is directly usable in databases or automation processes.
By extracting data only from the zones of interest, accuracy improves, making it highly beneficial for documents with repetitive layouts like invoices or forms.
How Does Zonal OCR Work?
Zonal OCR involves several steps, each contributing to accurate data extraction.
Document Pre-processing
Initially, documents undergo pre-processing to remove imperfections. Proper pre-processing ensures high OCR accuracy. Steps include cropping images, removing background noise, and enhancing readability.
Zone Definition
Users define “zones” within documents. This involves highlighting or selecting areas containing required data fields. For instance, identifying invoice numbers, dates, and amounts in invoices.
Data Extraction
The OCR software scans only defined zones, converting identified data fields into structured data formats. The structured output can be integrated directly into business systems without manual re-entry.
Verification and Correction
Extracted data undergoes automated or manual verification. IDP solutions, like KlearStack, use intelligent validation to minimize errors, enhancing overall accuracy.
By clearly defining these steps, businesses ensure streamlined document processing, reducing manual effort significantly.
Important Benefits of Using Zonal OCR
Zonal OCR offers several substantial advantages over traditional OCR methods.
Increased Accuracy
Extracting data from predefined zones reduces misreads. It provides structured, usable data directly. It provides better data integrity in fields like financial figures and personal information.
Faster Document Processing
With predefined zones, document processing becomes swift. Businesses witness dramatic reductions in processing time compared to manual data entry. For example, invoice processing times can reduce from days to minutes.
Improved Data Management
Zonal OCR digitizes structured data, simplifying document storage, retrieval, and analysis. Businesses easily integrate extracted data into CRM, ERP, or other business intelligence tools.
Reduced Operational Costs
Automating manual data extraction tasks lowers other expenses. McKinsey reports businesses can reduce data processing costs by nearly 50% using automated OCR methods like Zonal OCR.
These benefits highlight the need for Zonal OCR in document-intensive tasks across different organizations.
Common Applications of Zonal OCR
Businesses across industries widely adopt Zonal OCR technology due to its targeted data extraction capabilities.
Invoice Processing
Invoices have structured layouts ideal for Zonal OCR. Businesses automate the capture of data fields like invoice number, amount, date, and vendor details accurately.
ID Card Digitization
Government and private sectors employ Zonal OCR for digitizing ID cards. Zonal OCR uses data capture techniques for key fields such as names, birthdates, and identification numbers accurately and quickly.
Purchase Order Automation
Structured documents like purchase orders benefit from Zonal OCR. Key data fields such as PO numbers, quantities, product details, and pricing are accurately captured to make supply chain processes more focused.
Banking and Finance
Financial institutions utilize Zonal OCR to process bank statements, checks, and loan documents efficiently. Structured financial data becomes instantly accessible for analysis and decision-making.
These diverse applications underline the practicality and effectiveness of Zonal OCR in real-world scenarios.

Limitations and Challenges of Zonal OCR
Despite advantages, Zonal OCR faces certain practical limitations.
- Fixed Position Requirement: Zones must remain consistent. Changes in document layout significantly reduce accuracy.
- Quality Dependency: Poor-quality scans or images hinder data extraction accuracy.
- Complex Data Fields: Difficulties arise with multi-line or repeating fields.
To address these challenges, businesses may opt for advanced AI-based OCR solutions like KlearStack, capable of adaptive data extraction.
Why Should You Choose KlearStack?
Zonal OCR addresses structured document data extraction needs. However, typical Zonal OCR solutions fall short with varying layouts and complex data fields. KlearStack offers advanced OCR solutions overcoming these issues with AI and machine learning.
Key Benefits:
- Template-Free Data Extraction: Works seamlessly across varied document layouts.
- Self-Learning Algorithms: Improves extraction accuracy continuously.
- Real-Time Data Insights: Provides immediate, actionable business intelligence.
Proven Performance:
- Up To 99% Accuracy: Guaranteed high-quality data extraction.
- 85% Cost Savings: Substantial reduction in operational expenses.
- 500% Operational Efficiency: Dramatic improvements in workflow productivity.
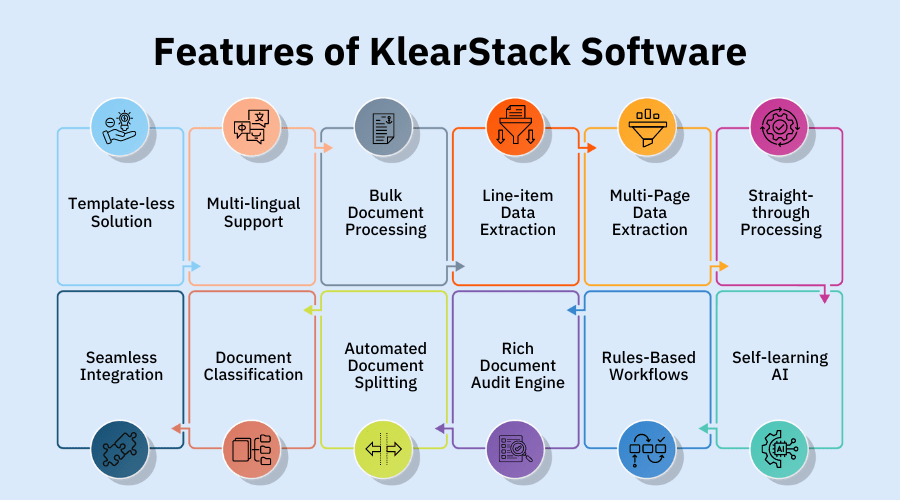
KlearStack’s solution simplifies complex data extraction.
Ready to automate your document processing? Book a Free Demo Call Now!
Conclusion
Zonal OCR significantly enhances structured document data extraction, improving accuracy, efficiency, and cost-effectiveness. Selecting advanced AI-driven solutions like KlearStack ensures:
- Reduced manual effort and processing time.
- Enhanced data accuracy and operational productivity.
- Substantial cost reduction and improved ROI.
Integrating Zonal OCR provides clear competitive advantages for businesses in document-intensive industries.
FAQs Zonal OCR
Zonal OCR extracts specific structured data fields from predefined zones in scanned documents accurately.
Zonal OCR typically handles printed text; specialized OCR solutions are necessary for accurate handwritten data extraction.
No, Zonal OCR requires consistent document layouts; accuracy declines significantly with layout changes.
KlearStack combines Zonal OCR with AI, adapting dynamically to various document layouts for enhanced accuracy.






